

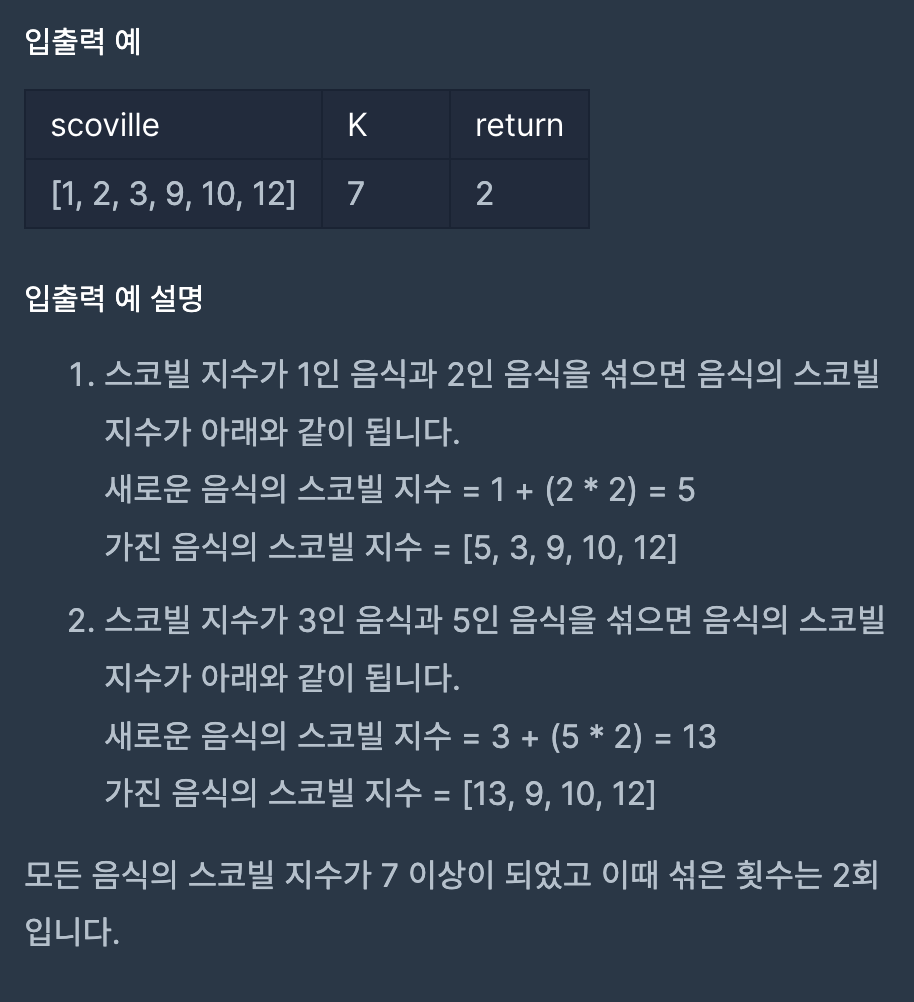
처음에 풀었던건 list를 이용해서 풀었다. 근데 역시 매번 sort를 시켜줘야 하니 확실히 성능면에서 떨어질 것이라 생각했는데
역시 테스트케이스는 다 맞았으나 효율성 면에서 시간초과가 났다.
package Programmers;
import java.util.*;
public class ProgrammingBasic {
public static void main(String[] args) {
int[] scoville = {1, 2, 3, 9, 10, 12};
int K = 7;
System.out.println(solution(scoville, K));
}
public static int solution(int[] scoville, int K) {
int answer = 0;
List<Integer> scovlist = new ArrayList<>();
for (int value : scoville) {
scovlist.add(value);
}
/*
모든 음식의 스코빌 지수를 K이상으로 만들기
가장 맵지 않은 음식의 스코빌 지수 + 두번쨰로 맵지 않은 음식의 스코빌 지수 * 2
모든 음식의 스코빌 지수가 K이상 될때까지 반복
scoville 정렬
2개가 1개로 변한다(2개 제외 후 한개 더하기)
i 인덱스 + i+1인덱스 * 2
만약 리스트가 2개 미안이면 return -1
*/
while (true) {
Collections.sort(scovlist);
if (scovlist.get(0) >= K) {
break;
}
if (scovlist.size() < 2) {
return -1;
}
int first = scovlist.get(0);
int second = scovlist.get(1);
scovlist.remove(0);
scovlist.remove(0);
scovlist.add(0, first + second * 2);
answer++;
}
return answer;
}
}
그래서 고민을 하다 우선순위 큐를 사용하기로 했다.
우선순위 큐는 힙 자료구조로 구현되는데 힙은 완전 이진트리의 일종이므로 각 노드가 자식 노드보다 우선순위가 높거나 같도록 유지된다.
그렇기 때문에
삽입 삭제의 경우 시간복잡도가 O(log n)이 나온다.
하지만 배열이나 리스트를 사용해서 매번 정렬하는 경우에 삽입은 O(1)이지만
정렬에 O(nlog n)의 시간이 소요된다.
그리고 우선순위 큐는 요소가 추가될 때마다 실시간으로 정렬 상태를 유지한다.
그래서 최우선 요소를 가져오는데 O(1)만 소요된다.
import java.util.*;
class Solution {
public int solution(int[] scoville, int K) {
int answer = 0;
PriorityQueue<Integer> pq = new PriorityQueue<>();
for(int value : scoville){
pq.add(value);
}
while(pq.peek() < K){
if(pq.size() < 2){
return -1;
}
int first = pq.poll();
int second = pq.poll();
pq.add(first + second * 2);
answer++;
}
return answer;
}
}처음에 풀었던건 list를 이용해서 풀었다. 근데 역시 매번 sort를 시켜줘야 하니 확실히 성능면에서 떨어질 것이라 생각했는데
역시 테스트케이스는 다 맞았으나 효율성 면에서 시간초과가 났다.
package Programmers; import java.util.*; public class ProgrammingBasic { public static void main(String[] args) { int[] scoville = {1, 2, 3, 9, 10, 12}; int K = 7; System.out.println(solution(scoville, K)); } public static int solution(int[] scoville, int K) { int answer = 0; List<Integer> scovlist = new ArrayList<>(); for (int value : scoville) { scovlist.add(value); } /* 모든 음식의 스코빌 지수를 K이상으로 만들기 가장 맵지 않은 음식의 스코빌 지수 + 두번쨰로 맵지 않은 음식의 스코빌 지수 * 2 모든 음식의 스코빌 지수가 K이상 될때까지 반복 scoville 정렬 2개가 1개로 변한다(2개 제외 후 한개 더하기) i 인덱스 + i+1인덱스 * 2 만약 리스트가 2개 미안이면 return -1 */ while (true) { Collections.sort(scovlist); if (scovlist.get(0) >= K) { break; } if (scovlist.size() < 2) { return -1; } int first = scovlist.get(0); int second = scovlist.get(1); scovlist.remove(0); scovlist.remove(0); scovlist.add(0, first + second * 2); answer++; } return answer; } }
그래서 고민을 하다 우선순위 큐를 사용하기로 했다.
우선순위 큐는 힙 자료구조로 구현되는데 힙은 완전 이진트리의 일종이므로 각 노드가 자식 노드보다 우선순위가 높거나 같도록 유지된다.
그렇기 때문에
삽입 삭제의 경우 시간복잡도가 O(log n)이 나온다.
하지만 배열이나 리스트를 사용해서 매번 정렬하는 경우에 삽입은 O(1)이지만
정렬에 O(nlog n)의 시간이 소요된다.
그리고 우선순위 큐는 요소가 추가될 때마다 실시간으로 정렬 상태를 유지한다.
그래서 최우선 요소를 가져오는데 O(1)만 소요된다.
import java.util.*; class Solution { public int solution(int[] scoville, int K) { int answer = 0; PriorityQueue<Integer> pq = new PriorityQueue<>(); for(int value : scoville){ pq.add(value); } while(pq.peek() < K){ if(pq.size() < 2){ return -1; } int first = pq.poll(); int second = pq.poll(); pq.add(first + second * 2); answer++; } return answer; } }